Why You Shouldn’t Use OFFSET and LIMIT For Your Pagination
Gone are the days when we wouldn’t need to worry about database performance optimization.
With the advance of times and every new entrepreneur wanting to build the next Facebook combined with the mindset of collecting every possible data-point to provide better Machine Learning predictions, we, as developers, need to prepare our APIs, better than ever, to provide reliable and efficient endpoints that should be able to navigate through huge amounts of data without a sweat.
If you have been doing backend or database architecture for a while you have probably already done paging queries, like this:

Right?
But if you did build your paginations such as this, I am sorry to say but you have been doing it wrong.
You don’t agree with me? You don’t need to. Slack, Shopify and Mixmax are paginating their APIs with this same concept we will be talking about today.
I challenge you to name a single backend developer who hasn‘t ever had to deal with OFFSET and LIMIT for pagination purposes. For pagination in MVPs and low-data listings it “just works“.
But when you want to build reliable and effective systems from the scratch, you might as well do it right upfront.
Today we will be discussing what the problems are with the (wrongly) widely used implementations and how to achieve a performant pagination.
What is wrong with OFFSET and LIMIT?
As we briefly explored in the past paragraphs, OFFSET and LIMIT work great for projects with low to no data usage.
The issue arises when your database starts gathering more data than your server can store in memory and you still need to paginate performantly through them all.
For that to happen the database will need to perform an inefficient Full Table Scan everytime you request a pagination (insertions and deletes may happen meanwhile and we don’t want outdated data!).
What is a Full Table Scan? A Full Table Scan (aka Sequential Scan) is a scan made in the database where every row in a table is sequentially read and the columns encountered are then checked for the validity of a condition. This type of Scan is known to be the slowest due the heavy amount of I/O reads from the disk consisting on multiple seeks as well as costly disk to memory transfers.
That means that if you have 100.000.000 users and you are requesting an OFFSET of 50.000.000, it will need to fetch all those records (that will not even be needed!), put them in memory, and only after, get the 20 results specified in the LIMIT.
So, to show a pagination like this in a website:
50.000 to 50.020 of 100.000
It would need to fetch 50.000 rows first. See how inefficient this is?
If you don’t believe me, take a look at this fiddle I’ve created. In the left panel you have a base schema that will insert 100.000 rows for our test and in the right there are is problematic query and our solution. Just click Run on the top and compare the execution time of each. The #1 (problematic query) takes at least 30x the time of the second to run.
And it gets even much worst with more data. Check out my Proof Of Concept with 10M rows.
Now this should give you some knowledge on what happens behind the scenes. If you like what you are reading, subscribe here to get more content like this.
TLDR; The higher your OFFSET, the longer the query will take.
What You Should Use Instead
This is what you should use:

This is a Cursor based pagination.
Instead of storing current OFFSET and LIMIT locally and passing it with each request, you should be storing the last received primary key (usually an ID) and the LIMIT, so the query could end up being similar to this one.
Why? Because by explicitly passing the latest read row, you are telling your DB exactly where to start the search based on an efficient indexed key and won’t have to consider any rows outside of that range.
Take into example the following comparison:

Against our optimized version:

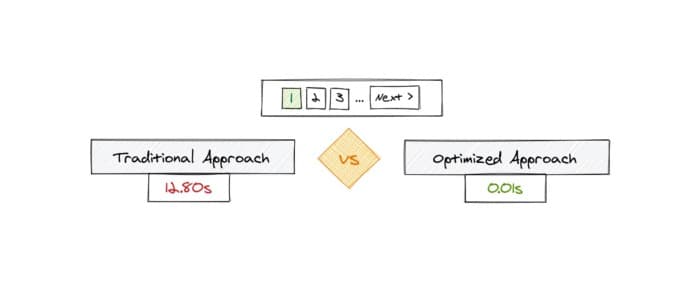
Exactly the same records were received, but the first query took 12.80sec and the second one took 0.01 sec. Can you realize the difference?
Caveats
For Cursor Pagination to work seamlessly, you will need to have a unique, sequential column (or columns), like a unique integer ID and this might be a deal-breaker in some specific cases.
As always, my advice would be to always think about the pros and cons of each table architecture and which kind of queries you will need to perform in each one. If you need to deal with a lot of related data in your queries, Lists article by Rick James might provide you deeper guidance.
If the issue we have in hands is related to not having a primary key, like if we had a many-to-many relationship table, the traditional approach of OFFSET/LIMIT is always available for these cases, however that would reintroduce potential slower queries. So I would recommend using an auto-incremented primary key in tables that you would want paginated, even if it would be just for the sake of pagination. Conclusion
The main takeaway of this should be to always check how your queries perform whether it is with 1k rows or with 1M. Scalability is of extreme importance and if implemented correctly from the beginning could surely avoid many headaches in the future.
Oh. And please don’t forget to learn about indexes. And explain queries.
If you are looking on how to implement Cursor Pagination on ElasticSearch, feel free to check out the article ElasticSearch — This is how you should paginate your results.
If you liked this post, subscribe here to get more content like this.
This post was originally posted on ivopereira.net.
